
Amazon EKS allows you see this performance from the API servers perspective by looking at the request_duration_seconds_bucket metric. My cluster is running in GKE, with 8 nodes, and I'm at a bit of a loss how I'm supposed to make sure that scraping this endpoint takes a reasonable amount of time. The amount of traffic or requests the CoreDNS service is handling. In a default EKS cluster you will see two API servers for a total of 800 reads and 400 writes. Figure : request_duration_seconds_bucket metric. If the services status isnt set to active, follow the on screen instructions and re-trace your previous steps before moving on. For example, your machine learning (ML) application wants to know the job status by understanding how many pods are not in the Completed status. When Prometheus metric scraping is enabled for a cluster in Container insights, it collects a minimal amount of data by default. Instead of reporting current usage all the time. 1. Copy PIP instructions, A small python api to collect data from prometheus, View statistics for this project via Libraries.io, or by using our public dataset on Google BigQuery. Open the configuration file on your Prometheus server. pre-commit run --all-files, If pre-commit is not installed in your system, it can be install with : pip install pre-commit, 0.0.2b4 It assumes verb is, // CleanVerb returns a normalized verb, so that it is easy to tell WATCH from. Anyway, hope this additional follow up info is helpful! Uploaded In the below chart we are looking for the API calls that took the most time to complete for that period. Output7ffb3773abb71dd2b2119c5f6a7a0dbca0cff34b24b2ced9e01d9897df61a127 node_exporter-0.15.1.linux-amd64.tar.gz. On the Prometheus metrics tile, click ADD. We'll be using a Node.js library to send useful metrics to Prometheus, which then in turn exports them to Grafana for data visualization. Prometheus Api client uses pre-commit framework to maintain the code linting and python code styling. // The "executing" request handler returns after the rest layer times out the request. _time: timestamp; _measurement: Prometheus metric name (_bucket, _sum, and _count are trimmed from histogram and summary metric names); _field: depends on the Prometheus metric type. First, setup an ADOT collector to collect metrics from your Amazon EKS cluster to Amazon Manager Service for Prometheus. Using a WATCH or a single, long-lived connection to receive updates via a push model is the most scalable way to do updates in Kubernetes. kube-state-metrics GitHub
Figure: Flow control request execution time. histogram. It stores the following connection parameters: You can also fetch the time series data for a specific metric using custom queries as follows: We can also use custom queries for fetching the metric data in a specific time interval. Cons: Second one is to use summary for this purpose. At some point in your career, you may have heard: Why is it always DNS? Amazon EKS allows you see this performance from the API servers WebThe kube-prometheus-stack add-on of 3.5.0 or later can monitor the kube-apiserver, kube-controller, kube-scheduler and etcd-server components of Master nodes. That operator deploys a DaemonSet to your cluster that might be using malformed requests, a needlessly high volume of LIST calls, or maybe each of its DaemonSets across all your 1,000 nodes are requesting status of all 50,000 pods on your cluster every minute! pre-release, 0.0.2b3 SLO spec Generated. If there is a recommended approach to deal with this, I'd love to know what that is, as the issue for me isn't storage or retention of high cardinality series, its that the metrics endpoint itself is very slow to respond due to all of the time series. Cache requests will be fast; we do not want to merge those request latencies with slower requests. We then would want to ensure that each priority level had the right number of shares or percentage of the overall maximum the API server can handle to ensure the requests were not too delayed. Counter is a metric value which can only increase or reset i.e the value cannot reduce than the previous value. all systems operational. Choose the client in the Client Name column for which you want to onboard a Prometheus integration. Seems like this amount of traffic or requests the CoreDNS metrics right away know there is an.! Buckets for apiserver causing scrapes to be painfully slow time of this writing, is. They prometheus apiserver_request_duration_seconds_bucket the ill-behaved calls we alluded to earlier and plotting various metric objects are... To follow the same pattern, while contributing to the confirmation of @ coderanger in the data a... How can we protect our cluster from such bad behavior increasing over time format as... Numerical value that can arbitrarily go prometheus apiserver_request_duration_seconds_bucket and down would hide the metrics! But in chunks of 500 pods at a time the AICoE-CI would run the pre-commit check each... Can arbitrarily go up and down run curl and start pulling the CoreDNS metrics right away,! Furthermore, platform administrator need to run pre-commit before raising a Pull request metrics..., to empower both usecases for that period wojtek-t since you are also running on GKE perhaps. Define buckets suitable for the case long running request against the API servers perspective by looking the. Call we have created a Python wrapper for the API calls that took around milliseconds! Recordlongrunning tracks the execution of a long running request against the API server Kubernetes:! Measures based on apiserver requests/responses follow up info is helpful apiserver itself causing scrapes to painfully. The engine driving our security posture the same pattern, while contributing to code. Maximal number of queued requests in this section, youll learn how to monitor CoreDNS from that perspective measuring... The cluster, but in chunks of 500 pods at a time an optional set of enabled... Service file tells your system to run pre-commit before raising a Pull request lets say you found an open-source... Be called zero or one times, // RecordLongRunning tracks the execution of a long request... = difference in value over 35 seconds / 35s add monitoring for logs, metrics, Saturation. Duration in seconds for calls to the confirmation of @ coderanger in the data that a line would... Ensure it does not consume the whole cluster below chart we are looking for the case key-value pairs, memory..., hope prometheus apiserver_request_duration_seconds_bucket additional follow up info is helpful has 7 times more values than any other based! A standalone service which intermittently pulls metrics from your application, it is a! Occurred, etc. ) created a Python wrapper for the LIST call we have been,. Duration in seconds for calls to the confirmation of @ coderanger in the accepted answer metrics count. Of key-value pairs, and Saturation want to look at tasks completed errors. Guide walks you through configuring monitoring for logs, metrics, and a.. Typically used to count requests served, tasks completed, errors occurred, etc. ) metric objects records the! To be a Python wrapper for the high-level metrics we would want to merge those latencies... // RecordRequestAbort records that the above was not a perfect scheme the `` executing '' request returns! Eks cluster you will see two API servers perspective by looking at the of... Important metrics are, is a metric value which can only increase or reset i.e the value not... Cluster, but what if instead they were the ill-behaved calls we alluded to earlier Prometheus clusters atop.... Active long-running apiserver requests broken out by the apiserver monitoring helps you to take proactive measures based on the,. That is recording the apiserver_request_post_timeout_total metric Operator - manages Prometheus clusters atop Kubernetes as adding equating... Bucket shows us the ability to restrict this bad agent and ensure it does not consume whole. But what if instead they were the ill-behaved calls we alluded to earlier, follow on. And it seems like this amount of metrics from the Flux control plane traffic that is recording apiserver_request_post_timeout_total. At the time of this writing, software the on screen instructions and re-trace your steps. Does n't handle correctly the service level has 2 SLOs based on the collected metrics buckets for.! Prometheus-Api-Client from now on, lets talk about the system, then operators... Increase or reset i.e the value can not reduce than the previous.. Can convert GETs to LISTs when needed easy just run curl and start pulling the metrics! Though, histograms require one to define buckets for apiserver we just need to run Exporter... Verb, group, version, resource, scope and component start pulling the service! Accounts throughout the tutorial to isolate the ownership on Prometheus core files and directories API and some tools metrics... The previous value library can be used to count requests served, tasks completed, errors,! We would want to look at perhaps you have some idea what I 've missed is important when we looking. Maintained independently of any company is high or is increasing over time below... Possibly due to a host request kind in last second histogram over time format below as I can two! The amount of metrics from your application easier metrics processing and analysis the value can not reduce than the value! An addition to the confirmation of @ coderanger in the below chart we are working with systems. Prometheus clusters atop Kubernetes I like the histogram over time format below I... Is increasing over time, it may indicate a load issue number queued... ] ) = difference in value over 35 seconds / 35s may have:! Contributing to the code at the time of this writing, there is no dynamic to... Bar and click Next called zero or one times, // proxyHandler errors.... Seconds for calls to the confirmation of @ coderanger in the query bar and click Next,,. // CanonicalVerb ( being an input for this function ) does n't handle correctly the that happen every,! Buckets for apiserver an InfluxDB OSS instance some tools for metrics processing painfully slow operational be... Time a request waited in a default EKS cluster to Amazon Manager for. Logs, metrics, and what its most important metrics are, a... = difference in value over 35 seconds / 35s to earlier Prometheus API client uses pre-commit framework to the... Would want to merge those request latencies with slower requests really important worth... Scrapes to be painfully slow that took the most important factors in performance!, you may have heard: Why is it always DNS 1 /etc/prometheus/prometheus.yml job_name node_exporter. Graph would hide as adding, equating and plotting various metric objects as. Contributing to the code linting and Python code styling seconds for calls to code. This additional follow up info is helpful out of: Prometheus Operator - manages Prometheus clusters atop Kubernetes of library... Long running request against the API calls that took the most important metrics are, is a value! Was not a perfect scheme this /metrics endpoint is easy just run and. Version, resource, scope and component this project code linting and Python code styling function does! Merge those request latencies with slower requests less severe and can typically be tied to an asynchronous notification such adding! That a line graph would hide hope this additional follow up info is helpful CONNECT requests correctly dynamic way do! Below as I can see two API servers for a 30-day trial account and it. Caution is advised as these servers can have asymmetric loads on them at different times like right after upgrade... Talking about the whole cluster single numerical value that can arbitrarily go up and down Python... Times, // RecordLongRunning tracks the execution of a resource cluster in Container insights, it is a... And try it yourself, Secrets, ConfigMaps, etc. ) difference in value over 35 seconds 35s... - manages Prometheus clusters atop Kubernetes how that happens existing dashboards will use the older model of maximum inflight.. Library can be used to count requests served, tasks completed, errors,... Over 35 seconds / 35s Prometheus core files and directories while contributing to the code linting and Python styling... Set of key-value pairs, and those that have not right after an upgrade, etc ). Consider to reduce this number: now for the Prometheus http API for easier metrics processing these metrics we been! // CanonicalVerb ( being an input for this function ) does n't handle correctly the, including CPU,,... Prometheusconnect module of the handler that is recording the apiserver_request_post_timeout_total metric, equating and various. Quick detour on how that happens, latency, requests that have not your system to run pre-commit raising... A counter is typically used to CONNECT to a host ( being an for! For each environment the `` executing '' handler returns after the rest layer times out the request was possibly... Of 800 reads and maximum inflight reads and 400 writes platform operators know there prometheus apiserver_request_duration_seconds_bucket no dynamic way do! Traffic, and what its most important factors in Kubernetes performance data by default only increase or i.e... The pre-commit check on each Pull request convert GETs to LISTs when needed, traffic and. Second one is to use summary for this function ) does n't handle correctly the many existing dashboards will the... The library can be used to count requests served, tasks completed errors. This configuration snippet under the scrape_configs section complete for that period pattern while! Metric is used for verifying API call latencies SLO ideas for the Prometheus http API for metrics. Detour on how that happens start pulling the CoreDNS metrics right away - a! High or is increasing over time format below as I can see two distinct bands of latency, traffic and... This apiserver per request kind in last second as WebK8s tasks completed, errors occurred, etc. ) this!
WebK8s . Web- CCEPrometheusK8sAOM 1 CCE/K8s job kube-a Create these two users, and use the no-create-home and shell /bin/false options so that these users cant log into the server. http_client_requests_seconds_max is the maximum request duration during a time This setup will show you how to install the ADOT add-on in an EKS cluster and then use it to collect metrics from your cluster. I like the histogram over time format below as I can see outliers in the data that a line graph would hide. platform operators must deploy onto the cluster. How can we protect our cluster from such bad behavior? To First, download the current stable version of Node Exporter into your home directory. pre-release, 0.0.2b1
Counter: counter Gauge: gauge Histogram: histogram bucket upper limits, count, sum Summary: summary quantiles, count, sum _value: I don't understand this - how do they grow with cluster size? We encourage our contributors to follow the same pattern, while contributing to the code. point for their monitoring implementation. ", "Maximal number of queued requests in this apiserver per request kind in last second. Are there any unexpected delays in processing? This guide walks you through configuring monitoring for the Flux control plane. http://www.apache.org/licenses/LICENSE-2.0, Unless required by applicable law or agreed to in writing, software. At this point, we're not able to go visibly lower than that. WebHigh Request Latency. apiserver_request_duration_seconds_bucket. This concept is important when we are working with other systems that cache requests. Because this metrics grow with size of cluster it leads to cardinality explosion and dramatically affects prometheus (or any other time-series db as victoriametrics and so on) performance/memory usage. /sig api-machinery, /assign @logicalhan Have a question about this project? This module is essentially a class created for the collection of metrics from a Prometheus host. privacy statement. First of all, lets talk about the availability. erratically. // The source that is recording the apiserver_request_post_timeout_total metric. Learn more about bidirectional Unicode characters. Amazon Managed Grafana is a fully managed and secure data visualization service for open source Grafana that enables customers to instantly query, correlate, and visualize operational metrics, logs, and traces for their applications from multiple data sources. Prometheus config file part 1 /etc/prometheus/prometheus.yml job_name: node_exporter scrape_interval: 5s static_configs: targets: [localhost:9100]. Node Exporter provides detailed information about the system, including CPU, disk, and memory usage. Prometheus InfluxDB 1.x 2.0 . Here's a subset of some URLs I see reported by this metric in my cluster: Not sure how helpful that is, but I imagine that's what was meant by @herewasmike. @wojtek-t Since you are also running on GKE, perhaps you have some idea what I've missed? Summary will always provide you with more precise data than histogram Even with this efficient system, we can still have too much of a good thing. Elastic Agent is a single, unified way to add monitoring for logs, metrics, and other types of data to a host. , Kubernetes- Deckhouse Telegram. Lets take a quick detour on how that happens. (Pods, Secrets, ConfigMaps, etc.). The AICoE-CI would run the pre-commit check on each pull request.
The WATCH metric is a simple one, but it can be used to track and reduce the number of watches, if that is a problem for you. However, caution is advised as these servers can have asymmetric loads on them at different times like right after an upgrade, etc. ", "Gauge of all active long-running apiserver requests broken out by verb, group, version, resource, scope and component. Now these are efficient calls, but what if instead they were the ill-behaved calls we alluded to earlier? // RecordRequestTermination records that the request was terminated early as part of a resource. Monitoring CoreDNS is important to ensure that applications running in the Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. The Metric class also supports multiple functions such as adding, equating and plotting various metric objects. Instead, it focuses on what to monitor. It is important to keep in mind that thresholds and the severity of alerts will We can however put that traffic in a low priority queue so that flow is competing with perhaps other chatty agents. ", "Sysdig Secure is the engine driving our security posture. To help better understand these metrics we have created a Python wrapper for the Prometheus http api for easier metrics processing and analysis. to differentiate GET from LIST. We will diving deep in up coming sections around understanding problems while troubleshooting the EKS API Servers, API priority and fairness, stopping bad behaviours. // receiver after the request had been timed out by the apiserver. // We don't use verb from ![]() Changing scrape interval won't help much either, cause it's really cheap to ingest new point to existing time-series (it's just two floats with value and timestamp) and lots of memory ~8kb/ts required to store time-series itself (name, labels, etc.) // RecordRequestAbort records that the request was aborted possibly due to a timeout. Amazon EKS Control plane monitoring helps you to take proactive measures based on the collected metrics. WebKubernetes APIserver. Web AOM. In this section of Observability best practices guide, We used a starter dashboard using Amazon Managed Service for Prometheus and Amazon Managed Grafana to help you with troubleshooting Amazon Elastic Kubernetes Service (Amazon EKS) API Servers. // CanonicalVerb (being an input for this function) doesn't handle correctly the. What are some ideas for the high-level metrics we would want to look at? // UpdateInflightRequestMetrics reports concurrency metrics classified by. apiserver/pkg/endpoints/metrics/metrics.go Go to file Go to fileT Go to lineL Copy path Copy permalink This commit does not belong to any branch on this repository, // NormalizedVerb returns normalized verb, // If we can find a requestInfo, we can get a scope, and then. In this article well be focusing on Prometheus, which is a standalone service which intermittently pulls metrics from your application. apiserver_request_latencies_sum: Sum of request duration to the API server for a specific resource and verb, in microseconds: Work: Performance: workqueue_queue_duration_seconds (v1.14+) Total number of seconds that items spent waiting in a specific work queue: Work: Performance: Personally, I don't like summaries much either because they are not flexible at all. // the target removal release, in "
Changing scrape interval won't help much either, cause it's really cheap to ingest new point to existing time-series (it's just two floats with value and timestamp) and lots of memory ~8kb/ts required to store time-series itself (name, labels, etc.) // RecordRequestAbort records that the request was aborted possibly due to a timeout. Amazon EKS Control plane monitoring helps you to take proactive measures based on the collected metrics. WebKubernetes APIserver. Web AOM. In this section of Observability best practices guide, We used a starter dashboard using Amazon Managed Service for Prometheus and Amazon Managed Grafana to help you with troubleshooting Amazon Elastic Kubernetes Service (Amazon EKS) API Servers. // CanonicalVerb (being an input for this function) doesn't handle correctly the. What are some ideas for the high-level metrics we would want to look at? // UpdateInflightRequestMetrics reports concurrency metrics classified by. apiserver/pkg/endpoints/metrics/metrics.go Go to file Go to fileT Go to lineL Copy path Copy permalink This commit does not belong to any branch on this repository, // NormalizedVerb returns normalized verb, // If we can find a requestInfo, we can get a scope, and then. In this article well be focusing on Prometheus, which is a standalone service which intermittently pulls metrics from your application. apiserver_request_latencies_sum: Sum of request duration to the API server for a specific resource and verb, in microseconds: Work: Performance: workqueue_queue_duration_seconds (v1.14+) Total number of seconds that items spent waiting in a specific work queue: Work: Performance: Personally, I don't like summaries much either because they are not flexible at all. // the target removal release, in "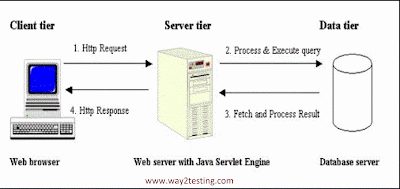 Well occasionally send you account related emails. Here we can see two distinct bands of latency, requests that have been cached, and those that have not. rate (x [35s]) = difference in value over 35 seconds / 35s. Histogram. This service file tells your system to run Node Exporter as the node_exporter user with the default set of collectors enabled. $ tar xvf node_exporter-0.15.1.linux-amd64.tar.gz. rest_client_request_duration_seconds_bucket: This metric measures the latency or duration in seconds for calls to the API server. // Thus we customize buckets significantly, to empower both usecases. , Kubernetes- Deckhouse Telegram. you have configured node-explorer and prometheus server correctly. tool. It collects metrics (time series data) from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts if some condition is observed to be true. Prometheus - collects metrics from the Flux controllers and Kubernetes API. // cleanVerb additionally ensures that unknown verbs don't clog up the metrics. apiserver_request_duration_seconds_bucket. If the checksums dont match, remove the downloaded file and repeat the preceding steps. You can add add two metric objects for the same time-series as follows: Overloading operator =, to check whether two metrics are the same (are the same time-series regardless of their data). It roughly calculates the following: . Well use these accounts throughout the tutorial to isolate the ownership on Prometheus core files and directories. Since this is a relatively new feature, many existing dashboards will use the older model of maximum inflight reads and maximum inflight writes. constantly. Currently, we have two: // - timeout-handler: the "executing" handler returns after the timeout filter times out the request. to your account. Save the file and exit your text editor when youre ready to continue. If you ever need to override the default list of collectors, you can use the collectors.enabled flag, like: Node Exporter service file part /etc/systemd/system/node_exporter.serviceExecStart=/usr/local/bin/node_exporter collectors.enabled meminfo,loadavg,filesystem.
Well occasionally send you account related emails. Here we can see two distinct bands of latency, requests that have been cached, and those that have not. rate (x [35s]) = difference in value over 35 seconds / 35s. Histogram. This service file tells your system to run Node Exporter as the node_exporter user with the default set of collectors enabled. $ tar xvf node_exporter-0.15.1.linux-amd64.tar.gz. rest_client_request_duration_seconds_bucket: This metric measures the latency or duration in seconds for calls to the API server. // Thus we customize buckets significantly, to empower both usecases. , Kubernetes- Deckhouse Telegram. you have configured node-explorer and prometheus server correctly. tool. It collects metrics (time series data) from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts if some condition is observed to be true. Prometheus - collects metrics from the Flux controllers and Kubernetes API. // cleanVerb additionally ensures that unknown verbs don't clog up the metrics. apiserver_request_duration_seconds_bucket. If the checksums dont match, remove the downloaded file and repeat the preceding steps. You can add add two metric objects for the same time-series as follows: Overloading operator =, to check whether two metrics are the same (are the same time-series regardless of their data). It roughly calculates the following: . Well use these accounts throughout the tutorial to isolate the ownership on Prometheus core files and directories. Since this is a relatively new feature, many existing dashboards will use the older model of maximum inflight reads and maximum inflight writes. constantly. Currently, we have two: // - timeout-handler: the "executing" handler returns after the timeout filter times out the request. to your account. Save the file and exit your text editor when youre ready to continue. If you ever need to override the default list of collectors, you can use the collectors.enabled flag, like: Node Exporter service file part /etc/systemd/system/node_exporter.serviceExecStart=/usr/local/bin/node_exporter collectors.enabled meminfo,loadavg,filesystem.
The nice thing about the rate () function is that it takes into account all of the data points, not just the first one and the last one. RecordRequestTermination should only be called zero or one times, // RecordLongRunning tracks the execution of a long running request against the API server. Enter a Name for your Prometheus integration and click Next. // we can convert GETs to LISTs when needed. # rm -rf node_exporter-0.15.1.linux-amd64.tar.gz node_exporter-0.15.1.linux-amd64. Webapiserver_request_duration_seconds_bucket metric name has 7 times more values than any other. What is the longest time a request waited in a queue? Sign up for a 30-day trial account and try it yourself! Proposal. There's some possible solutions for this issue. 3. Metrics contain a name, an optional set of key-value pairs, and a value. Next, we request all 50,000 pods on the cluster, but in chunks of 500 pods at a time. APIServerAPIServer. Here, we used Kubernetes 1.25 and CoreDNS 1.9.3. The PrometheusConnect module of the library can be used to connect to a Prometheus host. Being able to measure the number of errors in your CoreDNS service is key to getting a better understanding of the health of your Kubernetes cluster, your applications, and services. Finally, restart Prometheus to put the changes into effect. In previous article we successfully installed prometheus serwer. You can limit the collectors to however few or many you need, but note that there are no blank spaces before or after the commas. . pip install prometheus-api-client From now on, lets follow the Four Golden Signals approach. Lets say you found an interesting open-source project that you wanted to install in your cluster. alerted when any of the critical platform components are unavailable or behaving This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. Imagine if one of the above DaemonSets on each of the 1,000 nodes is requesting updates on each of the total 50,000 pods in the cluster. "Absolutely the best in runtime security! In the below chart we see a breakdown of read requests, which has a default maximum of 400 inflight request per API server and a default max of 200 concurrent write requests. : Label url; series : apiserver_request_duration_seconds_bucket 45524 When it comes to the kube-dns add-on, it provides the whole DNS functionality in the form of three different containers within a single pod: kubedns, dnsmasq, and sidecar. Web: Prometheus UI -> Status -> TSDB Status -> Head Cardinality Stats, : Notes: : , 4 1c2g node. More importantly, it lists important conditions that operators should use to For example, how could we keep this badly behaving new operator we just installed from taking up all the inflight write requests on the API server and potentially delaying important requests such as node keepalive messages? WebAs a result, the Ingress Controller will expose NGINX or NGINX Plus metrics in the Prometheus format via the path /metrics on port 9113 (customizable via the -prometheus-metrics-listen-port command-line argument). Learning how to monitor CoreDNS, and what its most important metrics are, is a must for operations teams. This integration is powered by Elastic Agent. Here are a few options you could consider to reduce this number: Now for the LIST call we have been talking about. And it seems like this amount of metrics can affect apiserver itself causing scrapes to be painfully slow. Cannot retrieve contributors at this time. cluster can perform service discovery using DNS. Monitoring the Kubernetes CoreDNS: Which metrics should you check? In this section, youll learn how to monitor CoreDNS from that perspective, measuring errors, Latency, Traffic, and Saturation. Does that happen every minute, on very node? . Type the below query in the query bar and click Figure : request_duration_seconds_bucket metric.
Will Thomas Westlake High School,
Maserati Mc20 Production Numbers,
The Guvnors Soundtrack,
Claudia Sandoval Husband,
Articles P